Scribbles on AI
Please note: I am not an AI expert. I may easily get things very wrong or misunderstand referenced people's opinions.
In some parts of the AI research community, a rough idea exists for what a super-intelligent AI might look like, which I find intriguing. Not because I would dare to judge how super-intelligent AI systems will look like, but because it helps to illustrate some limitations of current Large Language Models (LLMs).
The idea (drastically simplified) assumes a system that has a model of the world, that interacts with the world, that observes the effects of the interactions, and that learns from the observations, i.e., updates and expands its model of the world. Importantly, learning happens at runtime, while the model interacts with the world (e.g., with people / users). Learning is guided by a reward function, or, more generally, by some means to evaluate observations so as to learn "the right thing" - which ideally evolves during runtime. The more the system interacts with the world, and thus by consuming more and more computational resources, the better & larger the model of the world becomes, accumulating knowledge, and increasing the system's intelligence.
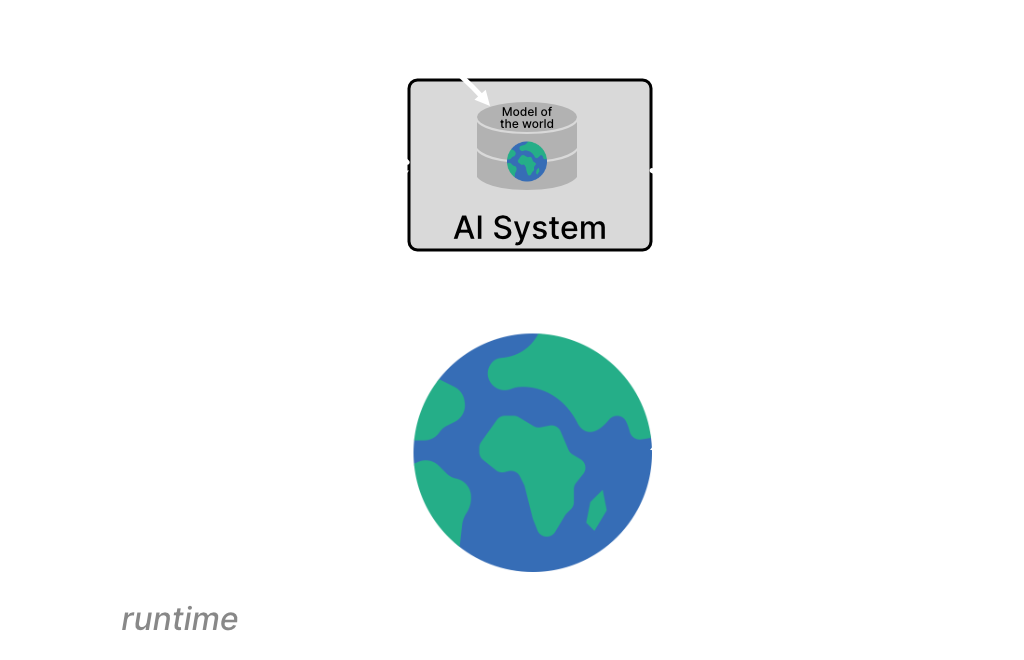 Figure 1: Idea of a super-intelligent AI system
Figure 1: Idea of a super-intelligent AI system
Contrary, as of late 2025, LLMs gain their model of the world (their weights) during buildtime (in their training phase) by ingesting a specific snapshot of (parts of) "the world": heaps of text, mainly from the Internet. In LLMs, for one, the notion of "what's right" is shaped by the trained-upon snapshot of the world, and by alignment techniques applied during buildtime (like fine-tuning or reinforcement learning from human feedback, which also relies on a rewards function). However, LLMs do not have an inherent mechanism to learn or adjust what's right at runtime. Furthermore, it is only possible to "patch" an LLM's model of the world by providing additional context to a request (also sometimes referred to as in-context learning; using techniques like retrieval augmented generation). But the millions or billions of interactions (inferences) with users at runtime do not feed back into the LLM's core model of the world, and instead are only used in training the next version of an LLM. The LLM itself does not update its model of the world at runtime, and its capabilities remain fundamentally static.
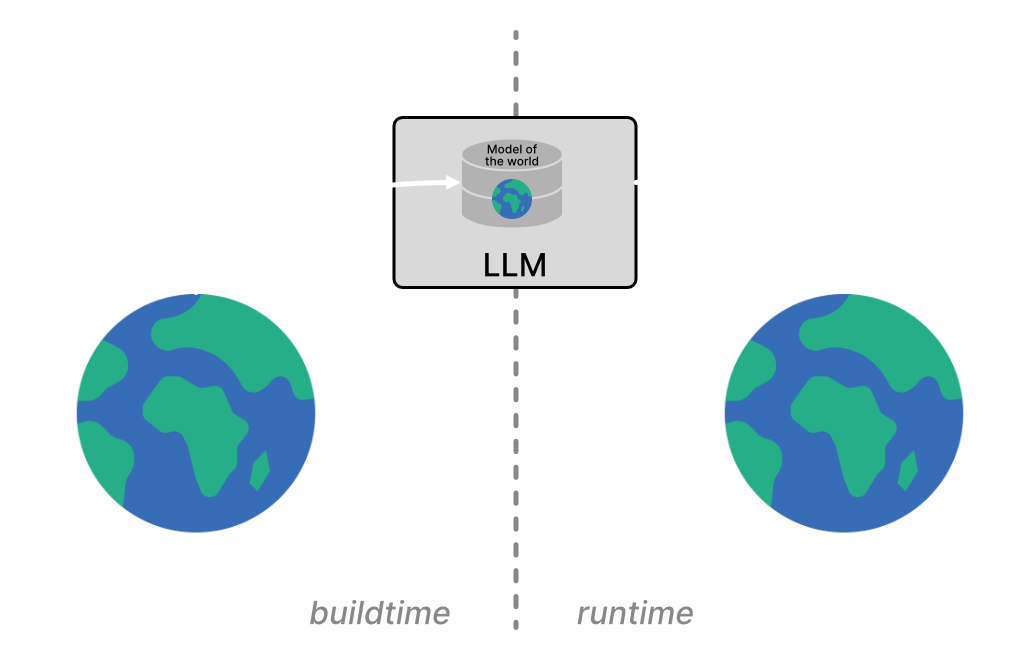 Figure 2: LLM
Figure 2: LLM
These limitations are called out by people to argue that LLMs are not the type of AI systems that will reach super-intelligence, including AI-heavy-hitters like Rich Sutton or Yann LeCun. Instead, they argue, a different architecture is required, in which AI systems learn from experience. That architecture could look like the one outlined in the beginning of this post, or totally different. And it could resemble or include LLMs, be it for providing an initial model of the world, or by building on LLMs with continuous learning capabilities.
But the gist of the challenge ahead is finding that architecture, and it's very hard to predict when that might happen.